Après avoir mis en place l’infrastructure de base et l’exposition sécurisée des services, une étape cruciale dans la gestion d’un homelab est la mise en place d’un système de monitoring complet. Dans cet article, je vais détailler les différents outils que j’utilise pour surveiller et gérer mon infrastructure : Portainer pour la gestion des conteneurs, Prometheus et Grafana pour la collecte et la visualisation des métriques, et Glance pour avoir une vue d’ensemble rapide de mon homelab.
Portainer : Gestion Centralisée des Conteneurs #
Pourquoi Portainer ? #
Portainer est une interface web qui simplifie considérablement la gestion des conteneurs Docker. Dans le contexte d’un homelab où de nombreux services sont conteneurisés, Portainer offre plusieurs avantages clés :
- Interface graphique intuitive pour gérer les conteneurs
- Vue d’ensemble de tous les hôtes Docker
- Gestion des volumes et des réseaux
- Déploiement rapide de nouveaux conteneurs
- Monitoring des ressources en temps réel
Architecture et Déploiement #
Mon installation de Portainer suit une architecture agent/serveur :
- Serveur Portainer : Déployé sur
vm_buckobserver - Agents Portainer : Installés sur toutes les VMs qui exécutent Docker
Le déploiement est automatisé via Ansible :
- name: Setup portainer
hosts: vm_buckobserver
become: true
tasks:
- name: Deploy Portainer
docker_container:
name: portainer
image: portainer/portainer-ce:latest
ports:
- "8000:8000"
- "9443:9443"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- portainer_data:/dataLes agents sont déployés sur les autres VMs avec une configuration similaire, permettant au serveur Portainer central de communiquer avec tous les hôtes Docker de mon infrastructure.
- name: Deploy Portainer agent
command:
cmd: >
docker run -d
-p 9001:9001
--name portainer_agent
--restart=always
-v /var/run/docker.sock:/var/run/docker.sock
-v /var/lib/docker/volumes:/var/lib/docker/volumes
-v /:/host
portainer/agent:latestA la fin, il ne me reste plus qu’à configurer les environnements à travers l’interface graphique et j’obtiens un beau recap des mes vms :

Prometheus et Grafana : Métriques et Visualisation #
Le Trio du Monitoring #
Mon système de monitoring repose sur trois composants complémentaires :
- Node Exporter : Collecte les métriques système de chaque VM
- Prometheus : Agrège et stocke les métriques
- Grafana : Visualise les données sous forme de tableaux de bord
Pourquoi Cette Stack ? #
Cette combinaison est devenue un standard de l’industrie pour plusieurs raisons :
- Scalabilité : Peut gérer des milliers de métriques
- Flexibilité : Support de multiples sources de données
- Granularité : Métriques détaillées personnalisables
- Alerting : Système d’alertes sophistiqué
Déploiement et Configuration #
Le déploiement est orchestré via Ansible en plusieurs étapes :
- Installation de Node Exporter sur chaque VM worker :
- name: Setup Node Exporter on workers
hosts: workers
become: true
tasks:
- name: Start Node Exporter with Docker Compose
shell: |
docker compose -f /home/ubuntu/node-exporter/docker-compose.yml up -d- Configuration de Prometheus sur le contrôleur :
scrape_configs:
- job_name: node
static_configs:
- targets: [{% for ip in groups['workers'] %}'{{ ip }}:9100', {% endfor %}]- Dashboards Grafana prédéfinis pour visualiser :
- Utilisation CPU/RAM par VM
- Espace disque disponible
- Trafic réseau
- État des conteneurs Dockerbeau
- Métriques système (charge, température, etc.)
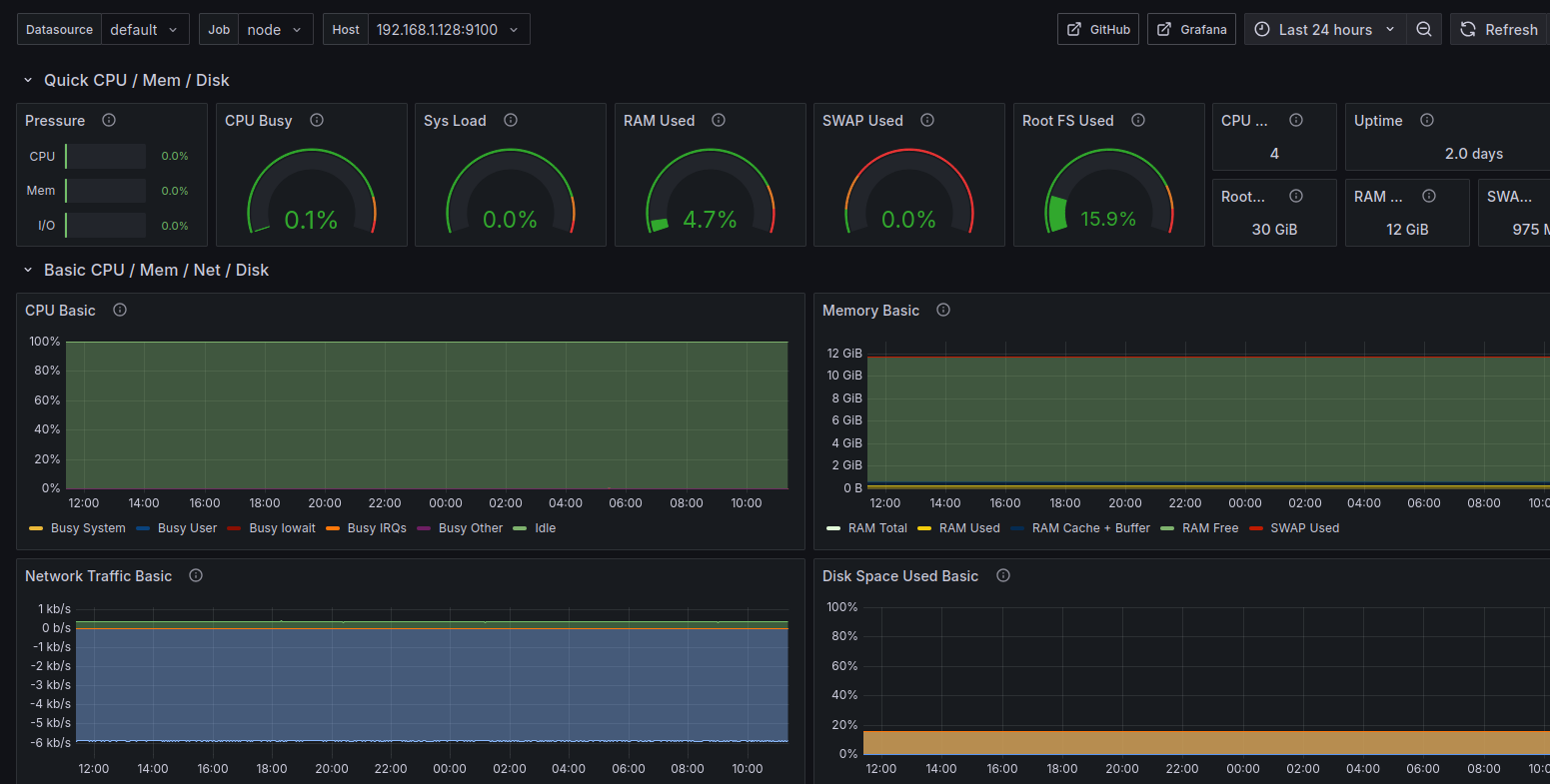
Penser à configurer la source. Après cela j’ai un dashboard efficace bien qu’un peu lourd, je prendrai du temps plus tard pour le rendre plus compact et surtout pour ajouter le monitoring de la mémoire GPU :
Glance : Vue d’Ensemble Rapide #
Pourquoi Glance ? #
Glance est un dashboard minimaliste que j’ai choisi pour avoir une vue d’ensemble rapide de mon infrastructure. Il complète Grafana en offrant :
- Une interface épurée et rapide
- Les informations essentielles en un coup d’œil
- Une configuration simple en YAML
Déploiement #
Le déploiement de Glance est également automatisé via Ansible :
- name: Setup Glance with Docker
hosts: vm_buckobserver
tasks:
- name: Ensure Glance container is running
docker_container:
name: glance
image: glanceapp/glance
ports:
- "8080:8080"
volumes:
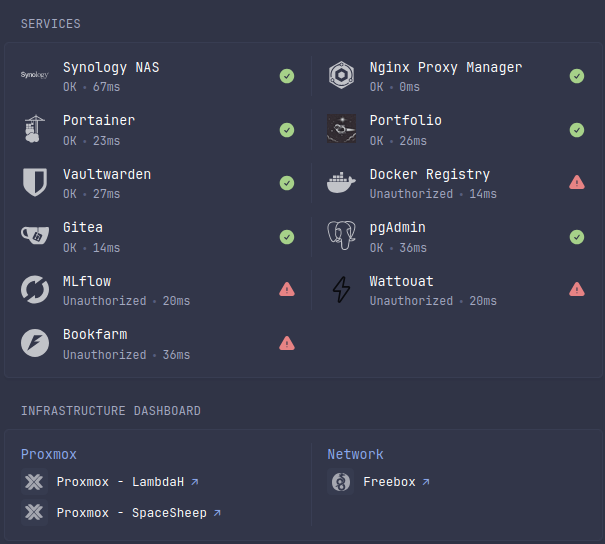
- /opt/glance/glance.yml:/app/glance.ymlLa configuration YAML permet de définir les services à surveiller et les métriques à afficher de manière simple et intuitive. Voilà un aperçu de ce que j’obtiens :
MLflow : Tracking des Expérimentations et Logs Centralisés #
Pourquoi MLflow ? #
MLflow joue un double rôle dans mon infrastructure :
-
Plateforme ML :
- Traçage des paramètres et métriques des expériences
- Versionnement des modèles
- Comparaison des résultats d’expérimentations
- Gestion du cycle de vie des modèles ML
-
Serveur de Logs Centralisé :
- Agrégation des logs de tous les services
- Interface unifiée de consultation
- Capacité de recherche et filtrage
- Stockage structuré et persistant
Cette double utilisation permet de centraliser à la fois le monitoring ML et la gestion des logs dans une seule interface, simplifiant la maintenance et l’exploitation.
Architecture Multi-Usage #
L’architecture de MLflow a été adaptée pour supporter ces deux cas d’usage :
-
Tracking ML :
- Utilisation classique via l’API Python de MLflow
- Stockage des métriques et paramètres dans SQLite
- Conservation des artefacts dans un volume dédié
-
Logging Standard :
- Utilisation de MLflow comme backend de logging
- Structuration des logs comme des “runs” MLflow
- Tags et métriques pour catégoriser les logs
- Exploitation des fonctionnalités de recherche de MLflow
Configuration et Déploiement #
Le déploiement via Ansible est configuré pour supporter les deux usages :
- name: Deploy MLflow in Docker
hosts: vm_buckobserver
become: true
tasks:
- name: Create MLflow directories
file:
path: "{{ item }}"
state: directory
mode: '0755'
loop:
- /mlflow/artifacts # Pour les modèles et artefacts ML
- /mlflow/data # Pour la DB SQLite
- /mlflow/logs # Pour les logs des services
- name: Create MLflow Docker container
docker_container:
name: mlflow
image: registry.spacesheep.ovh/mlflow-server:latest
ports:
- "5000:5000"
env:
MLFLOW_BACKEND_STORE_URI: "sqlite:////mlflow/data/mlflow.db"
MLFLOW_ARTIFACT_ROOT: "/mlflow/artifacts"
MLFLOW_LOGGING_DIR: "/mlflow/logs"
volumes:
- "/mlflow/artifacts:/mlflow/artifacts"
- "/mlflow/data:/mlflow/data"
- "/mlflow/logs:/mlflow/logs"Je peux ensuite utiliser mon serveur pour log ce que je veux, il suffit de le configurer dans le code, par exemple en python :
def setup_mlflow_autolog(tracking_uri=tracking_uri, experiment_name="unknown"):
"""
Configure MLflow pour un serveur distant avec authentification.
Args:
tracking_uri (str): URI de suivi du serveur MLflow.
experiment_name (str): Nom de l'expérience MLflow.
"""
os.environ['MLFLOW_TRACKING_USERNAME'] = mlflow_login
os.environ['MLFLOW_TRACKING_PASSWORD'] = mlflow_password
mlflow.set_tracking_uri(tracking_uri)
mlflow.set_experiment(experiment_name)
mlflow.sklearn.autolog(log_datasets=False)
print(f"MLflow configuré pour suivre l'URI : {tracking_uri}")
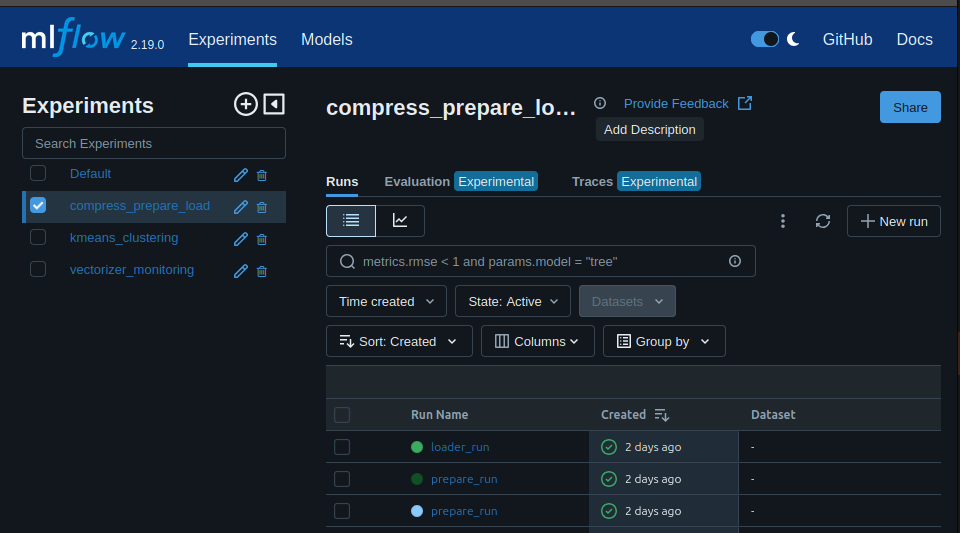
print(f"Expérience active : {experiment_name}")Et je peux suivre tout ça dans mon dashboard :
Avantages de cette Approche #
L’utilisation de MLflow comme solution unifiée présente plusieurs avantages :
-
Interface Unique :
- Moins d’outils à maintenir
- Formation simplifiée pour les utilisateurs
- Cohérence dans la présentation des données
-
Fonctionnalités Avancées :
- Recherche full-text dans les logs
- Filtrage par tags et métriques
- Visualisation des tendances
- Export et partage facilités
-
Extensibilité :
- Ajout facile de nouveaux services
- Possibilité d’enrichir les logs avec des métriques
- Integration avec d’autres outils via l’API REST
Tableau de Bord Unifié #
L’ensemble de ces outils est accessible via mon reverse proxy Nginx, chacun ayant son sous-domaine dédié. Cette organisation permet d’avoir une vue complète de mon infrastructure à différents niveaux de détail :
- Glance pour la vue d’ensemble rapide
- Portainer pour la gestion des conteneurs
- Grafana pour l’analyse approfondie des métriques
- MLflow pour le suivi des expérimentations ML et la gestion des logs
Conclusion #
La mise en place d’un système de monitoring complet est essentielle pour maintenir un homelab sain et réactif. La combinaison de Portainer, Prometheus/Grafana, Glance et MLflow me permet de :
- Détecter rapidement les problèmes
- Optimiser l’utilisation des ressources
- Planifier les évolutions nécessaires
- Maintenir une vue d’ensemble claire de l’infrastructure
- Suivre et optimiser mes expérimentations ML
Les prochains articles se concentreront sur la mise en place des services pour le stockage de tout ce que je voudrais potentiellement héberger.